这一篇打算将core部分的例子说完,这都是基于《opencv2.4.9tutorial.pdf》中的core部分,其实这些例子后期都很稳定的,也就是说就算是2.3.1和2.4.10 ,这几个例子不会变,变化的是新增函数啊什么的,所以无需担心这里的例子是否不适用新版本(opencv3按照他们小组的意思每次数字大变动,都会有很大的改变opencv3的alpha版本介绍说是重新定义了API,而且在CPU上进行了效果提升,在GPU上可以透明加速,也就是你在编程的时候不知道是在GPU上)。
看了下opencv3自带的tutorial,大部分也都还是差不多。本文是想将那些零散的例子能够更加的脱水,就是只说其中的几个精髓的函数。这是core部分的例子,虽然之前所有例子都码了一遍,不过觉得暂时自己用不到 【离散傅里叶变换】,所以这里没放进来,有兴趣的可以自己去看看。
正文:
一、计时函数
需要头文件#include"opencv2/core/core.hpp"
double t = (double)getTickCount();// 做点什么 ...t = 1000*((double)getTickCount() - t)/getTickFrequency();cout << "Times passed in seconds: " << t << endl;计时函数就和matlab中的tic ,toc一样,可以用来计算你的代码跑了多久,其实如果不是为了衡量效率什么的,这也是不怎么会用吧,首先进行提取当前电脑的时钟数,这时候返回的是基于上次某个事件(比如开机)开始计算的时钟数;
然后经过了一些操作,接着再次提取当前的时钟数并减去之前的数值,这时候是时钟数,需要除以时钟频率得到时间计数,记得这里是毫秒为单位,所以不要忘记乘以1000来表示多少秒。
二、矩阵掩码
需要头文件#include"opencv2/imgproc/imgproc.hpp"
这里的例子说的就是针对一个矩阵进行卷积,如果有过卷积神经网络(CNN)背景的就知道,通过对一副图像进行卷积然后得到另一个卷积后的图像。OpenCV中实现这一想法的就是filter2D过滤器,不过它是基于图像的,不像是matlab是基于完全的矩阵,所以当输入的是彩色图像的时候,它是在三个通道上独立的运行的:也就是对BGR三个通道分成三个矩阵,每个矩阵独立进行卷积,然后接着三个矩阵再次合并成一个新的图像。
Mat kern = (Mat_(3,3) << 0, -1, 0, -1, 5, -1, 0, -1, 0);
filter2D(I, K, I.depth(), kern );
imshow("your window's name",K); 上面第一行是先创建一个2D过滤器,在CNN中也叫做卷积核,机器学习中也叫做特征提取器。这里的创建方法虽然在前面一个博文中未介绍,不过觉得这个很像是特地为filter2D函数设计的,所以放在这里说,这是个运算符重定义,先Mat_<char>(3,3)先建立个3×3大小的矩阵,然后接着使用重定义操作符《来进行初始化,将得到的结果在赋值给核kern。 void filter2D(InputArray src, OutputArray dst, int ddepth, InputArray kernel, Point anchor=Point(-1,-1), double delta=0, int borderType=BORDER_DEFAULT )
filter2D的参数列表:输入图像,输出图像,输入图像的深度,卷积核,指定核的中心,卷积过程中加到每个像素上的值,指定在未定义区域上的行为。后两个参数是可选参数,也就是有默认形参的。
depth()表示的是位深度,就是每个元素是多少位的,是8位还是16位。

这个函数在图像上应用的是一个线性过滤器。支持in-place操作。当这个滑框部分超出了图像的时候,这个函数会按照具体的边界模式来插补外部的像素值。这个函数实际上是计算相关性,而不是卷积:

也就是说,这个kernel不是围绕着锚点镜像的。如果真的需要一个卷积,可以使用flip()来操作,然后设置新的锚点:(kernel.cols - anchor.x - 1, kernel.rows - anchor.y - 1) 。
这个函数是使用基于DFT的算法来应对大kernel(11×11或者更大)的,并且使用直接的算法(通过函数createLinearFIlter()实现的)来应对小kernel。
三、图像叠加
就是将两幅图进行不同程度的叠加,公式为:
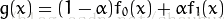
这里g(x)为输出图像,f(x)为对应的两幅图像,其实我觉得可以多福图像叠加,虽然没什么意义,不过原理上应该说的通。
beta = ( 1.0 - alpha );addWeighted( src1, alpha, src2, beta, 0.0, dst);
imshow("your window's name",dst); addWeighted函数就是将两个源图像加到一起,而且也是理解成每个对应通道对应相加。这里特别注意的是两个图像要一样大小,所以在读取不一样大小的可以通过设定不同的ROI或者对图像进行缩放来完成这个目的。 
四、防止数值溢出
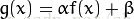
上面的式子就是针对一副图像进行图像对比度和亮度的调整,因为i是在一副图像上增加数值,如果BGR都增加到最大,那么就呈白色了,也就是增加每个通道上的亮度。对于这个操作,会有一定的几率出现结果超出255,那么就不能算是正常的值了,所以需要对结果进行限定,
for( size_t y = 0; y < image.rows; y++ ){ for( size_t x = 0; x < image.cols; x++ ) { for( size_t c = 0; c < 3; c++ ) { new_image.at (y,x)[c] = saturate_cast ( alpha*( image.at (y,x)[c] ) + beta ); } }} image.convertTo(new_image, -1, alpha, beta);上面的saturate_cast<uchar>()函数就是针对参数进行限定,乍一看还以为是cpp自带的类似static_castn那种,其实这个是opencv小组写的,
template<typename _Tp> static inline _Tp saturate_cast(uchar v) { return _Tp(v); }
template<typename _Tp> static inline _Tp saturate_cast(schar v) { return _Tp(v); } template<typename _Tp> static inline _Tp saturate_cast(ushort v) { return _Tp(v); } template<typename _Tp> static inline _Tp saturate_cast(short v) { return _Tp(v); }在<operations.hpp>头文件中,是通过使用cpp语言的截断功能来实现的,就是强制转换,比如一个超出uchar的数值,那么进行uchar的强制转换,直接丢弃超出的部分。
上面的convertTo()函数就是执行式子中的操作,第二个参数就是int rtype,如果是负数,那么输出图像就使用与输入图像一样的类型。
五、xml及yaml文件操作
这部分还是挺重要的,因为opencv中的很多分类器都是放在xml文件中的,而且xml适合web传输,所以这部分还是得会的。
XML和YAML的串行化分别采用两种不同的数据结构: mappings (就像STL map) 和 element sequence (比如 STL vector>。二者之间的区别在map中每个元素都有一个唯一的标识名供用户访问;而在sequences中你必须遍历所有的元素才能找到指定元素。
1、打开和关闭
string filename = "I.xml";FileStorage fs(filename, FileStorage::WRITE);\\...fs.open(filename, FileStorage::READ);
fs.release();上面是进行打开对应的文本进行读写,这里两种方法都可以(即在初始化的时候指定或者调用open函数),opencv针对xml和yaml文本有涉及到两个数据结构:FileStorage和FileNode。
FileStorage:在OpenCV中标识XML和YAML的数据结构是 。其中的第二个参数都以常量形式指定你要对文件进行操作的类型,包括:WRITE, READ 或 APPEND。文件扩展名决定了你将采用的输出格式。如果你指定扩展名如 .xml.gz ,输出甚至可以是压缩文件。
FIleNode:对于数据读取,可使用 和 数据结构。 的[] 操作符将返回一个 数据类型。如果这个节点是序列化的,我们可以使用 来迭代遍历所有元素。
2、普通读写
int itNr;fs["iterationNr"] >> itNr; //读操作或者 itNr = (int) fs["iterationNr"]; //读操作
fs << "iterationNr" << 100;//写操作如上面说的fs[]返回的是FileNode的数据类型,然后调用重载符>>来进行输出其中节点为["iterationNr"]的值到itNr中。
Mat R = Mat_如上面code,通过对fs进行建立“R”和“T”的节点,然后接着写入其数据;下面就是进行搜寻对应节点然后在读取数据。::eye (3, 3), T = Mat_ ::zeros(3, 1);fs << "R" << R; // 写 cv::Matfs << "T" << T;fs["R"] >> R; // 读 cv::Matfs["T"] >> T;
3、多数据读写
对于序列来说。写入:,在第一个元素前输出”[“字符,并在最后一个元素后输出”]“字符,中间就是所需要自己输入的数据:
fs << "strings" << "["; // 文本 - 字符串序列fs << "image1.jpg" << "Awesomeness" << "baboon.jpg";fs << "]"; // 序列结束
这里的结果就是:
如上面结果所示,在节点strings中,是没有顺序可言的,所以只能按照顺序读取然后进行比对结果。100 image1.jpg Awesomeness baboon.jpg
读取:采用FileNode数据结构先索引到对应的节点,然后采用Fileiterator迭代器进行一个一个的索引:
FileNode n = fs["strings"]; // 读取字符串序列 - 获取节点if (n.type() != FileNode::SEQ){ cerr << "strings is not a sequence! FAIL" << endl; return 1;}FileNodeIterator it = n.begin(), it_end = n.end(); // 遍历节点for (; it != it_end; ++it) cout << (string)*it << endl;//这里可以进行所需要的操作,比如对比或者什么的。 对于maps来说。 写入:与序列不同的在于采用”{“和”}“作为分隔符:
fs << "Mapping"; // 文本 - mappingfs << "{" << "One" << 1;fs << "Two" << 2 << "}"; 如上图,先建立个Mapping节点,但是后面的“{”告诉fs,将要采用maps的方式进行写入,所以这里前面多了两个可以索引的“one”和“two”,然后接着输入数据。 读取:
n = fs["Mapping"]; // 从序列中读取mapcout << "Two " << (int)(n["Two"]) << "; ";cout << "One " << (int)(n["One"]) << endl << endl;和上面一样先使用FileNode,找到节点,然后直接进行n["One"]的索引,这里返回值应该也是FileNode类型,然后转换成自己需要的类型就好。
如果要自定义数据类型,比如自定义类来包含一些数据和操作,为了便捷,记得重载<<,>>操作符。
更详细的部分请参考:http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/tutorials/core/file_input_output_with_xml_yml/file_input_output_with_xml_yml.html#fileinputoutputxmlyaml
六、基本绘图
这里介绍文本的打印和图形的绘制,首先介绍一个也许会用到的RNG类,然后介绍在图像上如何输出文字和基本的线啊,矩形啊,圆形啊什么的。
RNG rng( 0xFFFFFFFF );//或者直接RNG rng;
int x = (int)rng.uniform( a, b);第一行是建立个RNG的对象,然后进行初始化种子(可有可无,如果每次的种子都是相同的,那么结果就有比较性,所以matlab中都需要rand('state',0)在代码的开始);
第二个是随机提取个值,这个值是介于【a,b)之间的:
inline int RNG::uniform(int a, int b) { return a == b ? a : (int)(next()%(b - a) + a); } inline float RNG::uniform(float a, float b) { return ((float)*this)*(b - a) + a; } inline double RNG::uniform(double a, double b) { return ((double)*this)*(b - a) + a; }
可以看出,它的返回值就三个,所以如果不是这三个就需要进行强制转换了,这三行代码在<operations.hpp>中。
文本:
putText( image, "Testing text rendering", org, rng.uniform(0,8), rng.uniform(0,100)*0.05+0.1, randomColor(rng), rng.uniform(1, 10), lineType);putText()函数的参数列表:所打印的位置的图像,打印的文字,文字左下角的坐标,文字的字体的参数,文字的缩放,颜色,字体粗细程度,线的类型。
其实后面还有个可选的参数,这里说下lineType,在《refman》中的line()函数中具体介绍了,有三种形式分别为8、4、CV_AA。这三种。
Size textsize = getTextSize("OpenCV forever!", CV_FONT_HERSHEY_COMPLEX, 3, 5, 0); Point org((window_width - textsize.width)/2, (window_height - textsize.height)/2); 上面第一行就是提取文字的尺寸,采用getTextSize()函数 getTextSize()函数的参数列表:输入的文本字符串,fortFace(详见refman中的putText()函数部分的解释),字体的缩放大小(祥见第二个参数部分),同前两个参数,这是个指针表示相对于最底部的文本的点上y坐标的输出参数。
第二行就是建立文字需要摆放的左下角的坐标,这里的window_width和window_height是所被打印的图像的宽和高。
基本图形:
文字可以用来做图像的标记,图形可以用来框出感兴趣的区域。
线:void line(InputOutputArray img, Point pt1, Point pt2, const Scalar& color, int thickness=1, int lineType=LINE_8, int shift=0 );
参数列表:被打印的图像,起始点,终点,颜色,线粗细,线类型,平移。
int Drawing_Random_Lines( Mat image, char* window_name, RNG rng )
{ Point pt1, pt2; for( int i = 0; i < NUMBER; i++ ) { pt1.x = rng.uniform( x_1, x_2 ); pt1.y = rng.uniform( y_1, y_2 ); pt2.x = rng.uniform( x_1, x_2 ); pt2.y = rng.uniform( y_1, y_2 ); line( image, pt1, pt2, randomColor(rng), rng.uniform(1, 10), 8 ); imshow( window_name, image ); if( waitKey( DELAY ) >= 0 ) { return -1; } } return 0; }待续。。
http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/tutorials/core/basic_geometric_drawing/basic_geometric_drawing.html#drawing-1